By Sarah Wrenn
 At 5:50 PM on May 9, 2015, a fire ignited in one of two main transformers for the Unit 3 Reactor at Indian Point Energy Center. These transformers carry electricity from the main generator to the electrical grid. While the transformer is part of an electrical system external to the nuclear system, the reactor is designed to automatically shut down following a transformer failure. This system functioned as designed and the reactor remains shut down with the ongoing investigation. Concurrently, oil (dielectric fluid) spilled from the damaged transformer into the plant’s discharge canal and some amount was also released into the Hudson River. On May 19, Fred Dacimo, vice president for license renewal at Indian Point and Bill Mohl, president of Entergy Wholesale Commodities, stated the transformer holds more than 24,000 gallons of dielectric fluid. Inspections after the fire revealed 8,300 gallons have been collected or were combusted during the fire. As a result, investigators are working to identify the remaining 16,000 gallons of oil. Based on estimates from the Coast Guard supported by NOAA, up to approximately 3,000 gallons may have gone into the Hudson River.
At 5:50 PM on May 9, 2015, a fire ignited in one of two main transformers for the Unit 3 Reactor at Indian Point Energy Center. These transformers carry electricity from the main generator to the electrical grid. While the transformer is part of an electrical system external to the nuclear system, the reactor is designed to automatically shut down following a transformer failure. This system functioned as designed and the reactor remains shut down with the ongoing investigation. Concurrently, oil (dielectric fluid) spilled from the damaged transformer into the plant’s discharge canal and some amount was also released into the Hudson River. On May 19, Fred Dacimo, vice president for license renewal at Indian Point and Bill Mohl, president of Entergy Wholesale Commodities, stated the transformer holds more than 24,000 gallons of dielectric fluid. Inspections after the fire revealed 8,300 gallons have been collected or were combusted during the fire. As a result, investigators are working to identify the remaining 16,000 gallons of oil. Based on estimates from the Coast Guard supported by NOAA, up to approximately 3,000 gallons may have gone into the Hudson River.
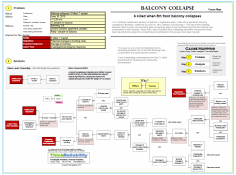
The graphic located here provides details regarding the event, facility layout and response.


Step 1. Define the Problem
There are a few problems in this event. Certainly, the transformer failure and fire are major problems. The transformer is an integral component to transfer electricity from the power plant to the grid. Without the transformer, production has been halted. In addition, there is an inherent risk of injury with the fire response. The site’s fire brigade was dispatched to respond to the fire and while there were no injuries, there was a potential for injury. In addition, the release of dielectric fluid and fire-retardant foam into the Hudson River is a problem. A moat around the transformer is designed to contain these fluids if released, but evidence shows that some amounts reached the Hudson River.
As shown in the timeline and noted on our problem outline, the transformer failure and fire occurred at 5:50 PM and was officially declared out 2.25 hours later.
As far as anything out of the ordinary or unusual when this event occurred, Unit 3 had just returned to operations after a shutdown on May 7 to repair a leak of clean steam from a pipe on the non-nuclear side of the plant. Also, it was noted that this is the 3rd transformer failure in the past 8 years. This frequency of transformer failures is considered unusual. The Wall Street Journal reported that the transformer that failed earlier this month replaced another transformer that malfunctioned and caught fire in 2007. Another transformer failed in 2010, which had been in operation for four years.
Multiple organizational goals were negatively impacted by this event. As mentioned above, there was a risk of injury related to the fire response. There was also a negative impact to the environment due to the release of dielectric fluid and fire-retardant foam. The negative publicity from the event impacts the organization’s customer service goal. A notification to the NRC of an Unusual Event (the lowest of 4 NRC emergency classifications) is a regulatory impact. For production/schedule, Unit 3 was shutdown May 9 and remains shutdown during the investigation. There was a loss of the transformer which needs to be replaced. Finally, there is labor/time required to address and contain the release, repair the transformer, and investigate the incident.
Step 2. Identify the Causes (Analysis)
Now that we’ve defined the problem in relation to how the organization’s goals were negatively impacted, we want to understand why.
The Safety Goal was impacted due to the potential for injury. The risk of injury exists because of the transformer fire.

The Regulatory Goal was impacted due to the notification to the NRC. This was because of the Unit 3 shutdown, which also impacts the Production/Schedule Goal. Unit 3 shutdown as this is the designed response to the emergency. This is the designed response because of the loss of the electrical transformer, which also impacts the Property/Equipment Goal. Why was the electrical transformer lost? Because of the transformer fire.

For the other goals impacted, Customer Service was because of the negative publicity which was caused by the containment, repair, investigation time and effort. This time and effort impacts the organization’s Labor/Time Goal. This time and effort was required because of the dielectric fluid and fire-retardant foam release. Why was there a release? Because the fluid and foam were able to access the river.

Why did the fluid and foam access the river?
The fire-retardant foam was introduced because the sprinkler system was ineffective. The transformer is located outside in the transformer yard which is equipped with a sprinkler system. Reports indicate that the fire was originally extinguished by the sprinklers, but then relit. Fire responders introduced fire-retardant foam and water to more aggressively address the fire. Some questions we would ask here include why was the sprinkler system ineffective at completely controlling the fire? Alternatively, is the sprinkler system designed to begin controlling the fire as an immediate response such that the fire brigade has time to respond? If this is the case, then did the sprinkler perform as expected and designed?
The transformer moat is designed to catch fluids and was unable to contain the fluid and the foam. When a containment is unable to hold the amount of fluid that is introduced, this means that either there is a leak in the containment or the amount of fluid introduced is greater than the capacity of the containment. We want to investigate the integrity of the containment and if there are any leak paths that would have allowed fluids to escape the moat. We also want to understand the volume of fluid that was introduced. The moat is capable of holding up to 89,000 gallons of fluid. A transformer contains approximately 24,000 gallons of dielectric fluid. What we don’t know is how much fire-retardant foam was introduced. If this value plus the amount of transformer fluid is greater than the capacity of the moat, then the fluid will overflow and can access the river. If this is the case, we also would want to understand if the moat capacity is sufficient, should it be larger? Also, is the moat designed such that an overflow will result in accessing the discharge canal and is this desired?
Finally, dielectric fluid accessed the river because the fluid was released from the transformer. Questions we would ask here are: Why was the fluid released and why does a transformer contain dielectric fluid? Dielectric fluid is used to cool the transformers. Other cooling methods, such as fans are also in place. The causes of the fluid release and transformer failure is still being investigated, but in addition to determining these causes, we would also ask how are the transformers monitored and maintained? The Wall Street Journal provided a statement from Jerry Nappi, a spokesman for Entergy. Nappi said both of unit 3’s transformers passed extensive electrical inspections in March. Transformers at Indian Point get these intensive inspections every two years. Aspects of the devices also are inspected daily.
Finally, we want to understand why was there a transformer fire. The transformer fire occurred because there was some heat source (ignition source), fuel, and oxygen. We want to investigate what was the heat source – was there a spark, a short in the wiring, a static electricity build up? Also, where did the fuel come from and is it expected to be there? The dielectric fluid is flammable, but are there other fuel sources that exist?

Step 3. Select the Best Solutions (Reduce the Risk)
What can be done? With the investigation ongoing, a lot of facts still need to be gathered to complete the analysis. Once that information is gathered, we want to consider what is possible to reduce the risk of having this type of event occur in the future. We would want to evaluate what can be done to address the transformer, implementing solutions to better maintain, monitor, and/or operate it. Focusing on solutions that will minimize the risk of failure and fire. However, if a failure does occur, we want to consider solutions so that the failure and fire does not result in a release. Further, we can consider the immediate response; do these steps adequately contain the release? Identifying specific solutions to the causes identified will provide reductions to the risk of future similar events.
Resources:
This Cause Map was built using publicly available information from the following resources.
De Avila, Joseph “New York State Calls for Tougher Inspections at Indian Point” http://www.wsj.com/articles/nuclear-regulatory-commission-opens-probe-at-indian-point-1432054561 Published 5/20/2015. Accessed 5/20/2015
“Entergy’s Response to the Transformer Failure at Indian Point Energy Center” http://www.safesecurevital.com/transformer_update/ Accessed 5/19/2015
“Entergy Plans Maintenance Shutdown of Indian Point Unit 3” http://www.safesecurevital.com/entergy-plans-maintenance-shutdown-of-indian-point-unit-3/ Published 5/7/2015. Accessed 5/19/2015
“Indian Point Unit 3 Safely Shutdown Following Failure of Transformer” http://www.safesecurevital.com/indian-point-unit-3-safely-shutdown-following-failure-of-transformer/ Published 5/9/2015. Accessed 5/19/2015
“Entergy Leading Response to Monitor and Mitigate Potential Impacts to Hudson River Following Transformer Failure at Indian Point Energy Center” http://www.safesecurevital.com/entergy-leading-response-to-monitor-and-mitigate-potential-impacts-to-hudson-river-following-transformer-failure-at-indian-point-energy-center/ Published 5/13/2015. Accessed 5/19/2015
“Entergy Continues Investigation of Failed Transformer, Spilled Dielectric Fluid at Indian Point Energy Center” http://www.safesecurevital.com/entergy-continues-investigation-of-failed-transformer-spilled-dielectric-fluid-at-indian-point-energy-center/ Published 5/15/2015. Accessed 5/19/2015
McGeehan, Patrick “Fire Prompts Renewed Calls to Close the Indian Point Nuclear Plant” http://www.nytimes.com/2015/05/13/nyregion/fire-prompts-renewed-calls-to-close-the-indian-point-nuclear-plant.html?_r=0 Published 5/12/2015. Accessed 5/19/2015
Screnci, Diane. “Indian Point Transformer Fire” http://public-blog.nrc-gateway.gov/2015/05/12/indian-point-transformer-fire/comment-page-2/#comment-1568543 Accessed 5/19/2015

 Clearly, there’s more to it. We can capture more details about this issue in a Cause Map, or visual form of root cause analysis. First, it’s important to capture the impact to the goals. In this case, the safety goal is impacted because of a serious risk to health and the environmental goal is impacted due to the spread of parasitic flatworms. The customer service goal (if we consider customers as all those who get water from the reservoir created by the dam) is impacted due to the outbreak of schistosomiasis.
Clearly, there’s more to it. We can capture more details about this issue in a Cause Map, or visual form of root cause analysis. First, it’s important to capture the impact to the goals. In this case, the safety goal is impacted because of a serious risk to health and the environmental goal is impacted due to the spread of parasitic flatworms. The customer service goal (if we consider customers as all those who get water from the reservoir created by the dam) is impacted due to the outbreak of schistosomiasis.