By Kim Smiley
![]() A worker at the bobsled track for the Sochi Winter Olympics was hit by a bobsled on February 13, 2014. The worker suffered two broken legs and a possible concussion, but is reported to be stable after undergoing surgery. There was also minor damage done to the track. Part of a lighting system suspended from the ceiling was replaced and time was needed to clean small plastic shards off the ice.
A worker at the bobsled track for the Sochi Winter Olympics was hit by a bobsled on February 13, 2014. The worker suffered two broken legs and a possible concussion, but is reported to be stable after undergoing surgery. There was also minor damage done to the track. Part of a lighting system suspended from the ceiling was replaced and time was needed to clean small plastic shards off the ice.
Investigation into this accident is still underway, but the information that is available in the media can be used to build an initial Cause Map. One of the advantages of using Excel to build Cause Maps is that they can be easily modified to incorporate additional information once the investigation is complete.
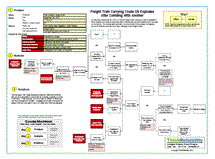
When beginning the Cause Mapping process, the first step is to fill in an Outline with the basic background information for an issue. How an incident impacted the overall organizational goals is also documented on the bottom half of the Outline. Once the Outline is completed, the Cause Map is built by asking “why” questions. (Click on “Download PDF” above to view a high level Cause Map and Outline for this accident.)
 So why was the worker hit by a bobsled? This occurred because a forerunner sled was sent down the track while the worker was on the track. The forerunner sled was on the track because they are used to test the track prior to training runs and competitions, and training was scheduled later that day. Forerunner sleds ensure that ice conditions are good and that all systems, like the timing system, are functional. People at the top of the track can’t see the entire track so there wasn’t an easy way for them to identify the position of the worker prior to running the sled. Initial reports are that the normal announcements were made to the workers prior to running the forerunner sled so it doesn’t appear that the people on the top of the track had any reason to suspect a problem.
So why was the worker hit by a bobsled? This occurred because a forerunner sled was sent down the track while the worker was on the track. The forerunner sled was on the track because they are used to test the track prior to training runs and competitions, and training was scheduled later that day. Forerunner sleds ensure that ice conditions are good and that all systems, like the timing system, are functional. People at the top of the track can’t see the entire track so there wasn’t an easy way for them to identify the position of the worker prior to running the sled. Initial reports are that the normal announcements were made to the workers prior to running the forerunner sled so it doesn’t appear that the people on the top of the track had any reason to suspect a problem.
The worker was on the track doing work to prepare it for the training runs and competition scheduled that day. We can safely assume that he was unaware that the forerunner sled was running the track at the same time. Investigators have determined that the worker was using a loud motorized air blower and believe he was unable to hear both the announcement and the approaching bobsled. Two other workers were also working on the track, but they were able to scramble out of danger as the bobsled approached. Until the investigation is complete, it won’t be clear if other factors were involved, but it seems the use of loud equipment played a role in the accident.
The final step in the Cause Mapping process is to find solutions to reduce the risk of a problem reccurring. It appears that the current method of letting workers know to clear the track isn’t adequate in all situations. Officials will need to modify the process, especially when loud equipment is in use, to ensure the safety of all workers. Workers need to be on the track at times in order to do their jobs and there needs to be a way to ensure they have moved to a safe location prior to any sled running the track.
It’s worth noting this is not the first time someone has been hit by a bobsled. In 2005, recent silver medalist skeleton racer Noelle Pikus-Pace was hit by a bobsled. She shattered a leg and ended up missing the 2006 Turin Olympics as a result. This accident occurred on a different track, but it highlights the dangers of bobsled tracks and the important of ensuring safety.